AI Path
Thoughts and notes about my learnings of the AI world. More than just red teaming notes, but a comprehension of AI systems, Machine Learning and Data Science. This is a live document and will be updated frequently

My AI Path
Since AI is here to stay, we need to adapt and adopt these new technologies.
I believe that it is important for us not just to learn how to attack these systems, but how to build, operate, tune and orchestrate them to properly get the best results out of them.
I will write later about some real world AI powered applications I have had targeted and compromised. Those are stories for another article.
These worlds are just some notes and thoughts about Agentic AI and LLMs. This post is not meant be a full guide or explanation of all the things that are involved in training these systems.
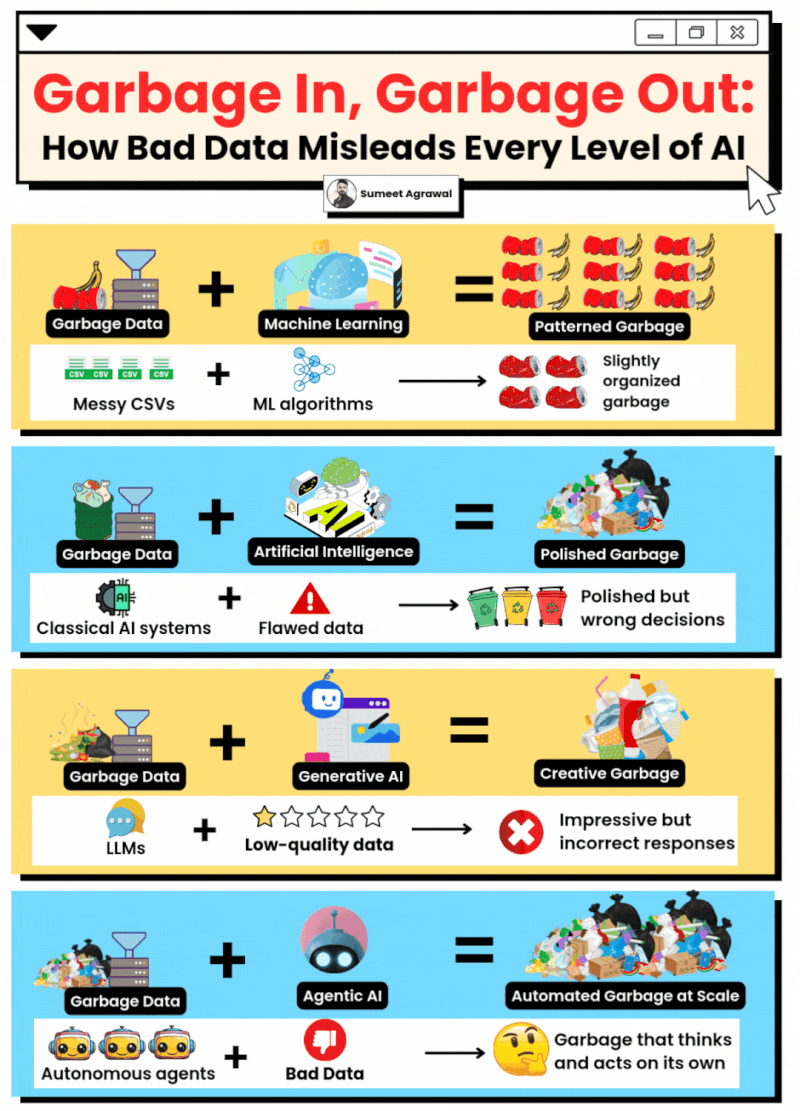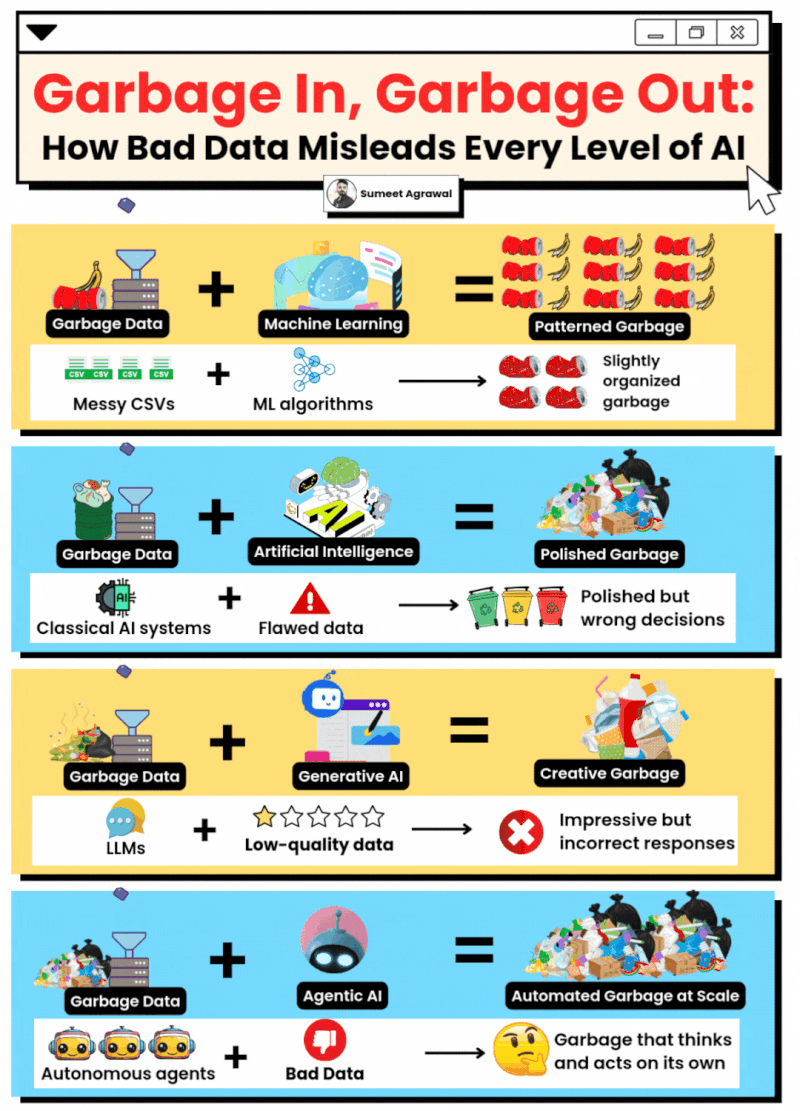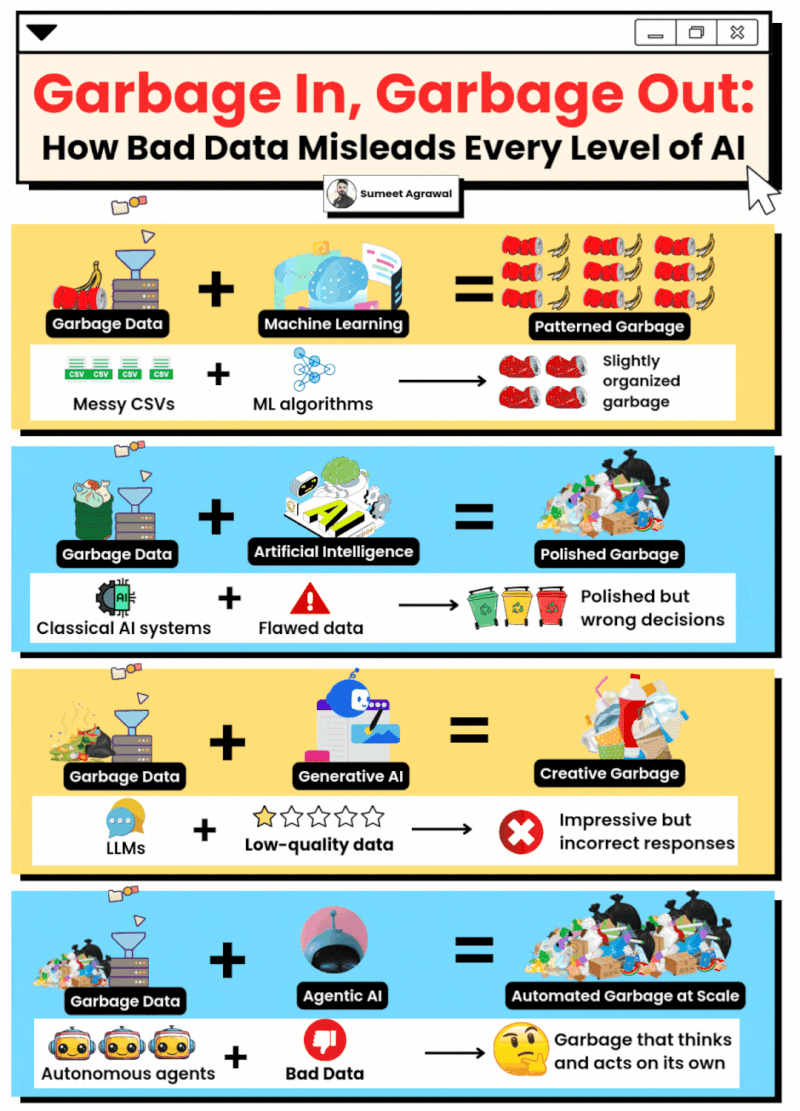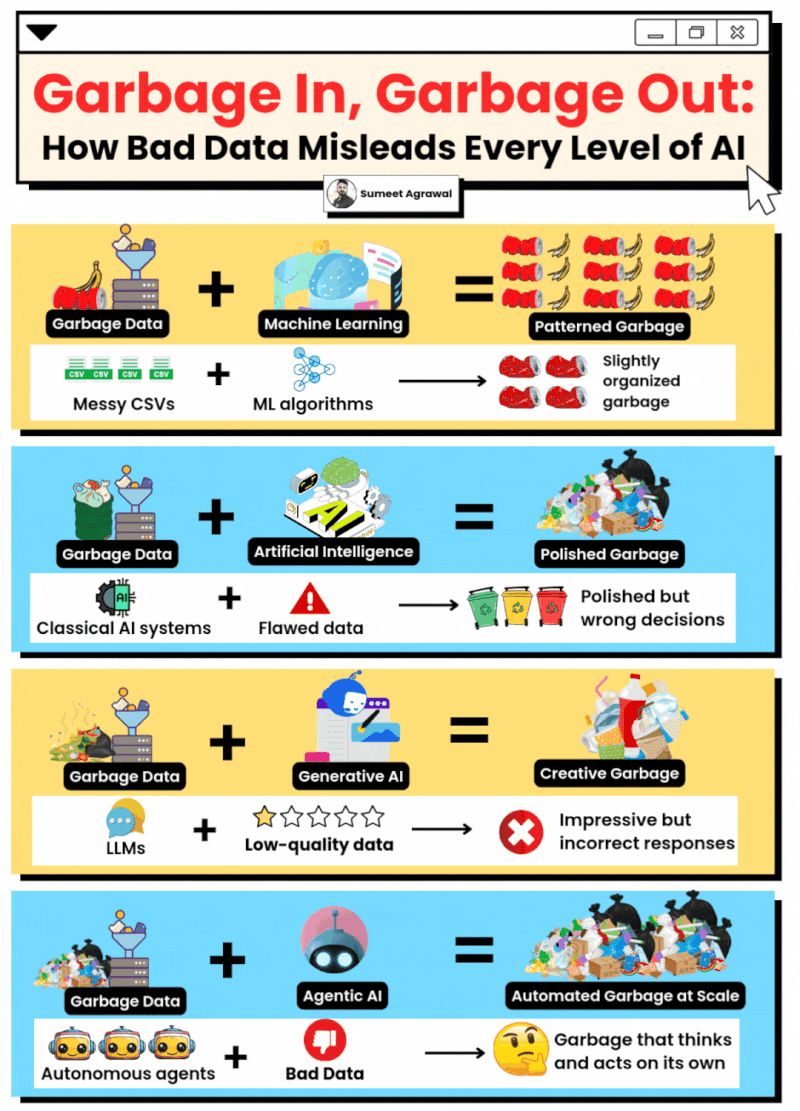
Not all the data is good data
Not always more is better.
The quality of the data used when training a model is very important. If you have inconsistent datasets that do not represent clearly a result, they could result in inconsistent and arbitrary responses from the models (although they are not deterministic).
Good datasets are clean, structured, accurate, and documented. Bad datasets feature missing values, duplicates, inconsistent formats (e.g., date formats changing), or significant bias.
Example of a bad dataset:
The following is an example of a garbage dataset for a fictional E-commerce Product & Pricing.
It illustrates common data quality issues that make a dataset unsuitable for AI training like duplicated values and entries, mixed data types, missing data, and more.
| ProductID | Item_Name | Category | Price_USD | Discount | Stock_Level | Last_Updated | User_Rating |
|---|---|---|---|---|---|---|---|
| 1001 | UltraPhone X | Electronics | 899.99 | 10% | 50 | 2023-01-01 | 4.5 |
| 1002 | superphone y | elect. | $750 | NULL | -5 | 01/05/23 | five |
| NULL | Leather Boots | Apparel | -45.00 | 0 | 100 | 2023-02-15 | 3.2 |
| 1004 | “Gaming Laptop” | NULL | 1200 | 150% | low | 2023-02-20 | 4.8 |
| 1005 | Coffee Maker | Kitchen | FREE | 0% | 20 | Unknown | 1.0 |
| 1006 | Desk Lamp | Home | 25.50 | 5 | 80 | 2022-12-31 | 999 |
| 1007 | 1007 | 1007 | 1007 | 1007 | 1007 | 1007 | 1007 |
| 1008 | Wireless Mouse | Electronics | 15.00 | 0% | 0 | 2029-10-12 | 4.0 |
| 1001 | UltraPhone X | Electronics | 899.99 | 10% | 50 | 2023-01-01 | 4.5 |
Another example of a bad dataset, in this case from Deeplearning.ai / AI for Everyone:
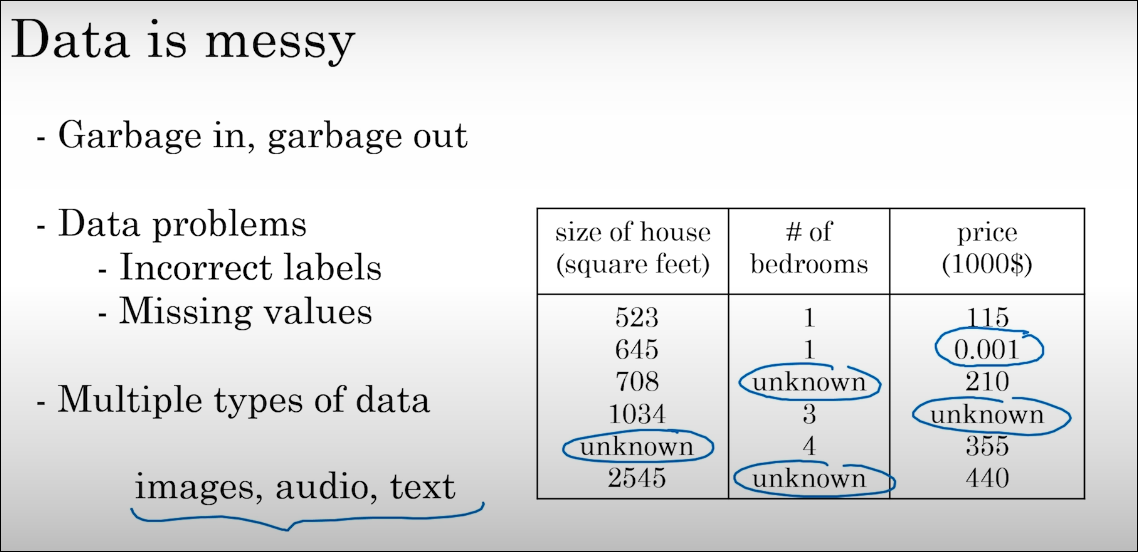 Messy Dataset
Messy Dataset
Supervised Machine Learning
A better way to share data for a machine learning system is using supervise learning. This is a type of machine learning where the model learns from labelled data, each input has a correct and expected output. Here is included the famous example of a cat and not a cat. Although, I prefer dogs…
 Supervised Machine Learning
Supervised Machine Learning
In Supervised Machine Learning, the key requirement is that every row of data must have a feature set (the inputs) and a corresponding label (the ground truth/target).
This example represents a dataset for a Loan Approval Model, where the goal is to predict whether a customer will default on a loan.
Dataset: “Customer_Credit_Training_Data”
| CustomerID | Annual_Income | Credit_Score | Debt_to_Income_Ratio | Years_Employed | Previous_Default | Approved_Label (Target) |
|---|---|---|---|---|---|---|
| C-482 | 85000 | 720 | 0.22 | 8 | No | Approved |
| C-910 | 32000 | 580 | 0.45 | 1 | Yes | Denied |
| C-115 | 120000 | 810 | 0.15 | 12 | No | Approved |
| C-633 | 45000 | 640 | 0.38 | 3 | No | Denied |
| C-209 | 55000 | 690 | 0.28 | 5 | No | Approved |
| C-741 | 28000 | 510 | 0.55 | 0 | Yes | Denied |
Context Matters A Lot
The transformer and its other components:
 LLM Visualization
LLM Visualization
We live in token economy in regards to Agentic AIs and LLMs.
Tokens in LLMs could be a word, phrase, sentence piece or bytes pair.
 Sample LLM Token Calculator
Sample LLM Token Calculator
Provide your AI agents as much context as possible about the tasks you about to perform or instruct them to do. Also, review the context windows of each AI provider to be tailored to your needs.
These are some values of the current AI providers and models:
| Model | Provider | Max Context Window | Max Output | Notes |
|---|---|---|---|---|
| Llama 4 Scout | Meta | 10,000,000 tokens | — | Largest known window (2026) |
| Grok 4 / 4.1 Fast | xAI | 2,000,000 tokens | — | Same window across variants |
| Gemini 2.5 Pro | 1,000,000 tokens | 64k | 2M beta in testing | |
| Gemini 2.5 Flash | 1,000,000 tokens | 8k | Optimized for speed | |
| GPT‑4.1 | OpenAI | 1,000,000 tokens | 32k | — |
| GPT‑4.1 Mini | OpenAI | 1,000,000 tokens | 32k | — |
| Llama 4 Maverick | Meta | 1,000,000 tokens | — | Free self‑host |
| Claude Opus 4.7 | Anthropic | 1,000,000 tokens | 128k | Confirmed in API docs and launch reports |
| GPT‑5 / GPT‑5.2 / Nano | OpenAI | 400,000 tokens | 128k | — |
| o3 | OpenAI | 200,000 tokens | 100k | — |
| Claude 4.6 (Opus/Sonnet) | Anthropic | 200,000 tokens | 64k | 1M beta for some tiers |
| Claude Haiku 4.5 | Anthropic | 200,000 tokens | — | — |
| DeepSeek R1 / V3 | DeepSeek | 128,000 tokens | — | Reasoning‑optimized |
| Mistral Large 3 | Mistral | 128,000 tokens | — | — |
| Qwen3‑235B | Alibaba | 128,000 tokens | — | — |
| GPT‑5.4 | OpenAI | 128,000 tokens | 16k | — |
| Kimi K2 | Moonshot | 256,000 tokens | — | Local‑LLM list |
| Qwen3 30B A3B / 235B A22B | Alibaba | 256,000 tokens | — | Local‑LLM list |
Knowledge Cutoffs
An LLM’s knowledge of the world is frozen at the time of its training. That’s why in some of the cases, Agentic AI models refer to the Internet for fresh knowledge and up to date data.
Tips for prompting
Although, there are different prompting techniques that are really effective,there is not a perfect prompt. Each person has different preferences and the best way to find a perfect prompt for you is through experimentation.
So, forget about those lists of the 20 prompts everyone should know…
Prompting process:
- Be clear and specific in prompt
- Think about why the result isn’t giving you the desired output
- Redefine your output
- Repeat
Caveats:
- Be careful with confidential information
- Validate the output
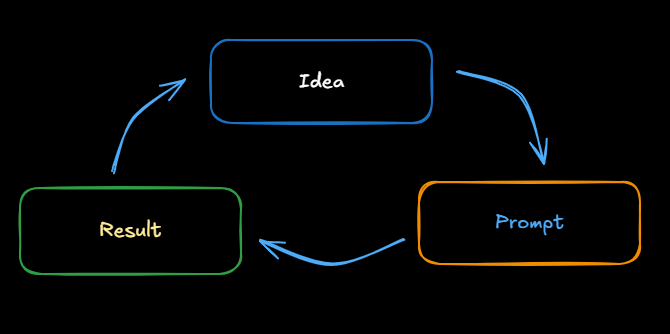 Illustrating Prompting Process
Illustrating Prompting Process
Lifecycle of a generative AI project
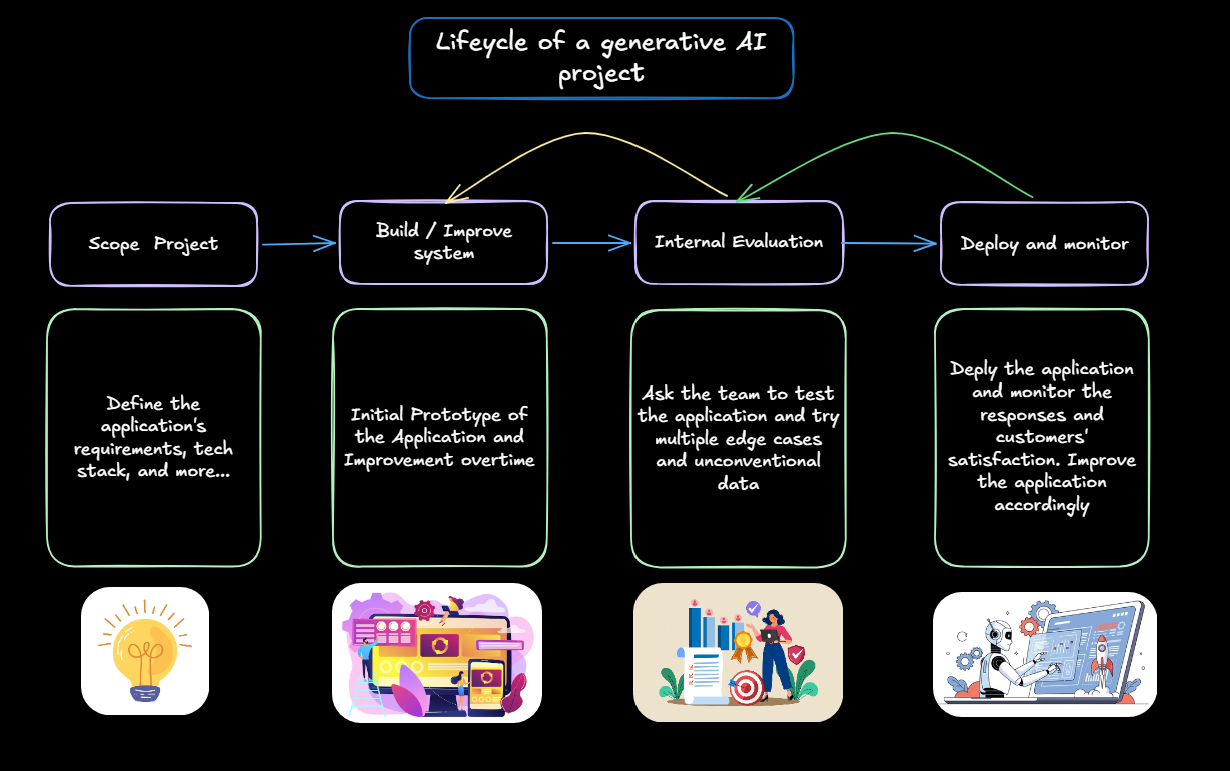 Understanding the lifecycle of an AI project
Understanding the lifecycle of an AI project
Retrieval Augmented Generation (RAG)
LLM and Agentic AI model may know a lot of information, but not all.
If you want to expand the knowledge of an LLM with specific details about your company, your preferences, your specific research and more. Retrieval Augmented Generation (RAG) is a technique that can be used to add that additional knowledge to your application.
RAG is mainly modifications to your prompt.
Example question:
- How many apple trees are in this field?
- -No RAG answer: I need more information about your location to provide a relevant answer.
- +RAG answer: There are 500 new apple trees in this field.
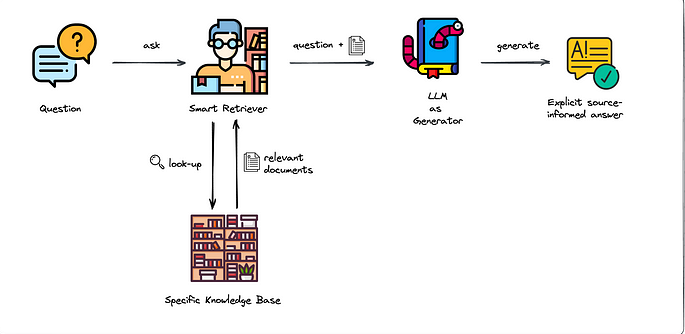 Answering domain-specific knowledge questions with RAG
Answering domain-specific knowledge questions with RAG
Fine-tuning
Fine-tuning is the process of adapting an existent pre-trained model to perform a specific task or update its weight with a specific domain knowledge through a systematic process.
Why to fine-tune a model if it is more expensive than RAG?
- Provide a set of specific knowledge to a model
- Instruct a model to prove certain responses base on the training data
- Improve tasks performance and produce better results and expected (still non-deterministic) outputs
- Reduce cost and resource usage by guiding a model to perform certain tasks
- Uncensored a model like for security research specializations and implementations
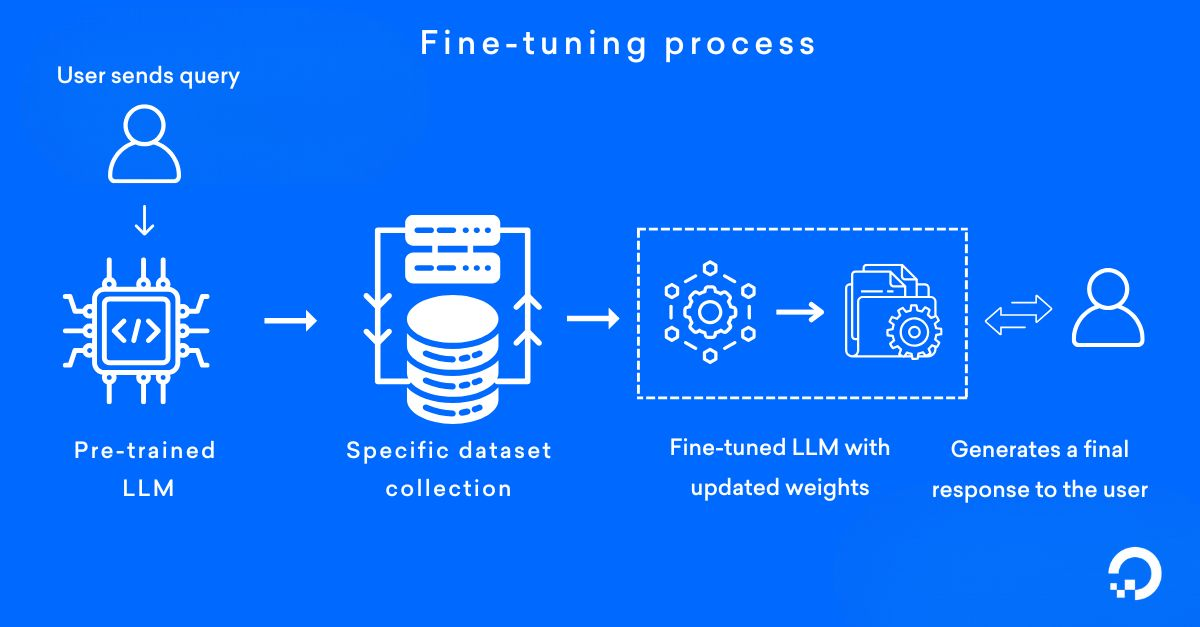 Fine-tuning process for general understanding
Fine-tuning process for general understanding
Usually, fine-tuning can work with 500 - 1000 data examples of high-quality labeled datasets with the clear definition of the task to perform.
Pre-Training
It is expensive and mostly performed by large companies these days.
It is not recommended for individuals and it requires huge amounts of data and computational resources.
 Illustrative image of pre-training a model
Illustrative image of pre-training a model